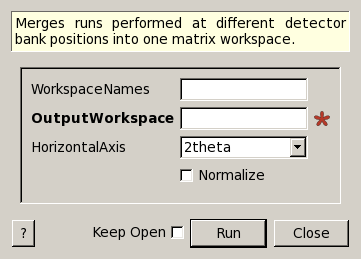
DNSMergeRuns dialog.
Table of Contents
| Name | Direction | Type | Default | Description |
|---|---|---|---|---|
| WorkspaceNames | Input | str list | List of Workspace names to merge. | |
| OutputWorkspace | Output | MatrixWorkspace | Mandatory | A workspace name to save the merged data. |
| HorizontalAxis | Input | string | 2theta | X axis in the merged workspace. Allowed values: [‘2theta’, ‘|Q|‘, ‘d-Spacing’] |
| Normalize | Input | boolean | False | If checked, the merged data will be normalized, otherwise the separate normalization workspace will be created. |
Warning
This algorithm is being developed for a specific instrument. It might get changed or even removed without a notification, should instrument scientists decide to do so.
This algorithm merges given matrix workspaces to a Workspace2D. The purpose of this algorithm is to merge the DNS diffraction mode data measured at different detector bank positions. The algorithm is not suitable to merge DNS single crystal diffraction data measured at different sample rotation angles.
Note
The OutputWorkspace will have no connection to the instrument. Part of the sample logs will be lost either. This algorithm can be executed at any step of the data reduction to view the result. However, further data reduction must be performed on the original workspaces.
As a result, following output will be produced:
Warning
Normalization workspaces are created by the LoadDNSLegacy v1 algorithm. It is responsibility of the user to take care about the same type of normalization (monitor counts or run duration) for all given workspaces.
Absolute value of the momentum transfer 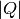 is calculated as
is calculated as
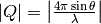
where 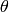 is the scattering angle and
is the scattering angle and  is the neutron wavelength.
is the neutron wavelength.
d-Spacing 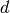 is calculated as:
is calculated as:
The input workspaces (WorkspaceNames) have to have the following in order to be valid inputs for this algorithm.
For the physically meaningful merge result, it is also important that these workspaces have the same slits size, polarisation, and flipper status. If some of these parameters are different, algorithm produces warning. If these properties are not specified in the workspace sample logs, no comparison is performed.
Example - Merge a set of selected runs
from os import listdir
from os.path import isfile, join, splitext
import re
import numpy as np
# path to the directory containing data files
mypath = "/path/to/data/dns/rc36b_standard_dz"
# filter the data files in the given directory
p = re.compile('^dz(\d{8})vana.d_dat$')
# we choose only the runs with 'x' polarisation
filelist = [str(i*6 + 29100501) for i in range(10)]
def is_in_filelist(fname, p, flist):
m = re.match(p, fname)
if m:
num = m.group(1)
return num in flist
else:
return False
datafiles = sorted([f for f in listdir(mypath) if isfile(join(mypath,f)) and is_in_filelist(f, p, filelist)])
# load data to workspaces
wslist = []
for f in datafiles:
try:
wname = splitext(f)[0]
#print "Processing ", wname # uncomment if needed
LoadDNSLegacy(Filename=join(mypath, f), OutputWorkspace=wname, Polarisation='x', Normalization='duration')
except RuntimeError as err:
print err
else:
wslist.append(wname)
# merge the given workspaces
merged = DNSMergeRuns(wslist, HorizontalAxis='2theta', Normalize=True)
mergedQ = DNSMergeRuns(wslist, HorizontalAxis='|Q|')
mergedD = DNSMergeRuns(wslist, HorizontalAxis='d-Spacing')
# print selected values from merged workspaces
two_theta = merged.extractX()[0]
print "First 5 2Theta values: ", two_theta[:5]
q = mergedQ.extractX()[0]
print "First 5 |Q| values: ", np.round(q[:5], 3)
d = mergedD.extractX()[0]
print "First 5 d values: ", np.round(d[:5], 3)
Output:
First 5 2Theta values: [ 7.5 8. 8.5 9. 9.5]
First 5 Q values: [ 0.249 0.266 0.282 0.299 0.315]
First 5 d values: [ 1.844 1.848 1.852 1.856 1.86 ]
Categories: Algorithms | PythonAlgorithms | MLZ | DNS
Python: DNSMergeRuns.py