LoadLiveData dialog.
Table of Contents
| Name | Direction | Type | Default | Description |
|---|---|---|---|---|
| Instrument | Input | string | Mandatory | Name of the instrument to monitor. Allowed values: [‘ALF’, ‘CRISP’, ‘ENGIN-X’, ‘ENGIN-X_EVENT’, ‘GEM’, ‘HET’, ‘HRPD’, ‘IMAT’, ‘INES’, ‘INTER’, ‘IRIS’, ‘LARMOR’, ‘LOQ’, ‘MAPS’, ‘MARI’, ‘MERLIN’, ‘MERLIN_EVENT’, ‘OSIRIS’, ‘PEARL’, ‘POLARIS’, ‘SANDALS’, ‘SURF’, ‘SXD’, ‘TOSCA’, ‘VESUVIO’, ‘LET’, ‘LET_EVENT’, ‘NIMROD’, ‘OFFSPEC’, ‘OFFSPEC_EVENT’, ‘POLREF’, ‘SANS2D’, ‘SANS2D_EVENT’, ‘WISH’, ‘HIFI’, ‘MUSR’, ‘EMU’, ‘ARGUS’, ‘CHRONUS’] |
| StartTime | Input | string | Absolute start time, if you selected FromTime. Specify the date/time in UTC time, in ISO8601 format, e.g. 2010-09-14T04:20:12.95 | |
| ProcessingAlgorithm | Input | string | Name of the algorithm that will be run to process each chunk of data. Optional. If blank, no processing will occur. | |
| ProcessingProperties | Input | string | The properties to pass to the ProcessingAlgorithm, as a single string. The format is propName=value;propName=value | |
| ProcessingScript | Input | string | A Python script that will be run to process each chunk of data. Only for command line usage, does not appear on the user interface. | |
| AccumulationMethod | Input | string | Add | Method to use for accumulating each chunk of live data. - Add: the processed chunk will be summed to the previous outpu (default). - Replace: the processed chunk will replace the previous output. - Append: the spectra of the chunk will be appended to the output workspace, increasing its size. Allowed values: [‘Add’, ‘Replace’, ‘Append’] |
| PreserveEvents | Input | boolean | False | Preserve events after performing the Processing step. Default False. This only applies if the ProcessingAlgorithm produces an EventWorkspace. It is strongly recommended to keep this unchecked, because preserving events may cause significant slowdowns when the run becomes large! |
| PostProcessingAlgorithm | Input | string | Name of the algorithm that will be run to process the accumulated data. Optional. If blank, no post-processing will occur. | |
| PostProcessingProperties | Input | string | The properties to pass to the PostProcessingAlgorithm, as a single string. The format is propName=value;propName=value | |
| PostProcessingScript | Input | string | A Python script that will be run to process the accumulated data. | |
| RunTransitionBehavior | Input | string | Restart | What to do at run start/end boundaries? - Restart: the previously accumulated data is discarded. - Stop: live data monitoring ends. - Rename: the previous workspaces are renamed, and monitoring continues with cleared ones. Allowed values: [‘Restart’, ‘Stop’, ‘Rename’] |
| AccumulationWorkspace | Output | Workspace | Optional, unless performing PostProcessing: Give the name of the intermediate, accumulation workspace. This is the workspace after accumulation but before post-processing steps. | |
| OutputWorkspace | Output | Workspace | Mandatory | Name of the processed output workspace. |
| LastTimeStamp | Output | string | The time stamp of the last event, frame or pulse recorded. Date/time is in UTC time, in ISO8601 format, e.g. 2010-09-14T04:20:12.95 |
This algorithm is called on a regular interval by the MonitorLiveData v1 algorithm. and the whole process is started by the StartLiveData v1 algorithm. It should not be necessary to call LoadLiveData directly.
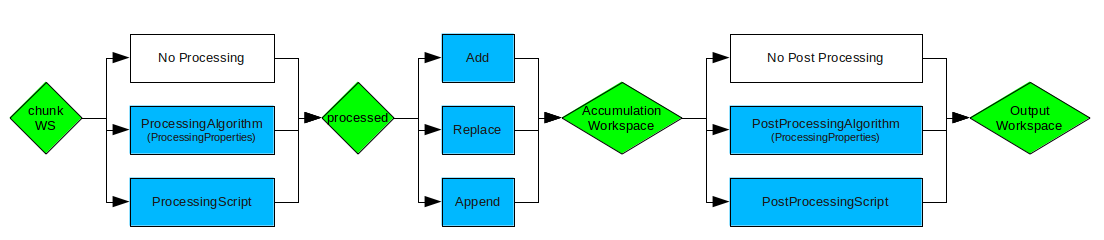
LoadLiveData_flow.png
Beware! If you select PreserveEvents and your processing keeps the data as EventWorkspaces, you may end up creating very large EventWorkspaces in long runs. Most plots require re-sorting the events, which is an operation that gets much slower as the list gets bigger (Order of N*log(N)). This could cause Mantid to run very slowly or to crash due to lack of memory.
LoadLiveData is not intended for usage directly, it is part of he process that is started using StartLiveData v1.
Categories: Algorithms | DataHandling | LiveData | Support