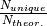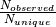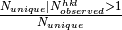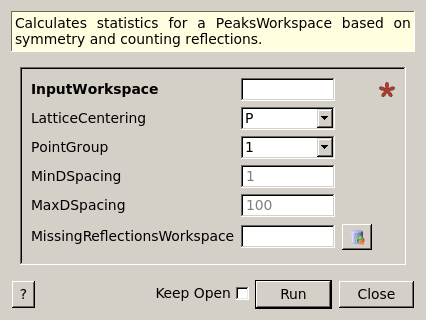
CountReflections dialog.
Table of Contents
| Name | Direction | Type | Default | Description |
|---|---|---|---|---|
| InputWorkspace | Input | PeaksWorkspace | Mandatory | A workspace with peaks to calculate statistics for. Sample with valid UB-matrix is required. |
| LatticeCentering | Input | string | P | Lattice centering of the cell. Allowed values: [‘P’, ‘C’, ‘A’, ‘B’, ‘I’, ‘F’, ‘Robv’, ‘Rrev’, ‘H’] |
| PointGroup | Input | string | 1 | Point group symmetry for completeness and redundancy calculations. Allowed values: [‘-1’, ‘-3’, ‘-3 r’, ‘-31m’, ‘-3m’, ‘-3m r’, ‘-3m1’, ‘-4’, ‘-42m’, ‘-43m’, ‘-4m2’, ‘-6’, ‘-62m’, ‘-6m2’, ‘1’, ‘112’, ‘112/m’, ‘11m’, ‘2’, ‘2/m’, ‘222’, ‘23’, ‘2mm’, ‘3’, ‘3 r’, ‘312’, ‘31m’, ‘32’, ‘32 r’, ‘321’, ‘3m’, ‘3m r’, ‘3m1’, ‘4’, ‘4/m’, ‘4/mmm’, ‘422’, ‘432’, ‘4mm’, ‘6’, ‘6/m’, ‘6/mmm’, ‘622’, ‘6mm’, ‘m’, ‘m-3’, ‘m-3m’, ‘m2m’, ‘mm2’, ‘mmm’] |
| MinDSpacing | Input | number | 1 | Minimum d-spacing for completeness calculation. |
| MaxDSpacing | Input | number | 100 | Maximum d-spacing for completeness calculation. |
| UniqueReflections | Output | number | Number of unique reflections in data set. | |
| Completeness | Output | number | Completeness of the data set as a fraction between 0 and 1. | |
| Redundancy | Output | number | Average redundancy in data set, depending on point group. | |
| MultiplyObserved | Output | number | Fraction of reflections with more than one observation. | |
| MissingReflectionsWorkspace | Output | PeaksWorkspace | Reflections in specified d-range that are missing in input workspace. |
This algorithm computes some crystallographic data set quality indicators that are based on counting reflections according to their Miller indices HKL. Intensity information is not required for these indicators, so that the algorithm can also be used with predicted data (for example generated by PredictPeaks v1).
According to the specified lattice centering and the resolution boundaries, a set of
theoretically measurable reflections is generated. How the reflections are mapped to
a set of 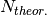 unique reflections depends on the supplied point group. Then the
unique reflections depends on the supplied point group. Then the
 actually observed peaks from the input workspace are assigned to their
respective unique reflection, yielding
actually observed peaks from the input workspace are assigned to their
respective unique reflection, yielding 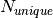 observed unique reflections.
observed unique reflections.
From this assignment it is possible to calculate the following indicators:
- Unique reflections:
- Completeness:
- Redundancy:
- Multiply observed reflections:
Furthermore, the algorithm optionally produces a list of missing reflections. In this list,
each missing unique reflection is expanded to all symmetry equivalents according to the point
group. For example, if the reflection family  was missing
with point group
was missing
with point group 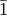 , the list would contain
, the list would contain  and
and  .
.
The reason for expanding the unique reflections is to make the list more useful as an input to PredictPeaks v1 again.
Note
This algorithm has some overlap with SortHKL v1, which computes some of the indicators this algorithm calculates, but in addition also evaluates intensity information. SortHKL only works with peaks that carry intensity data while this algorithm also works without intensities.
The usage example uses the same data as the usage test in SortHKL v1, but produces slightly different data, because some intensities in the input file are 0, so these reflections are ignored by SortHKL v1:
# Load example peak data and find cell
peaks = LoadIsawPeaks(Filename=r'Peaks5637.integrate')
FindUBUsingFFT(peaks, MinD=0.25, MaxD=10, Tolerance=0.2)
SelectCellWithForm(peaks, FormNumber=9, Apply=True, Tolerance=0.15)
OptimizeLatticeForCellType(peaks, CellType='Hexagonal', Apply=True, Tolerance=0.2)
# Run the SortHKL algorithm
unique, completeness, redundancy, multiple = CountReflections(peaks, PointGroup='-3m1',
LatticeCentering='Robv', MinDSpacing=0.205,
MaxDSpacing=2.08, MissingReflectionsWorkspace='')
print('Data set statistics:')
print(' Peaks: {0}'.format(peaks.getNumberPeaks()))
print(' Unique: {0}'.format(unique))
print(' Completeness: {0}%'.format(round(completeness * 100, 2)))
print(' Redundancy: {0}'.format(round(redundancy, 2)))
print(' Multiply observed: {0}%'.format(round(multiple*100, 2)))
Output:
Data set statistics:
Peaks: 434
Unique: 358
Completeness: 9.57%
Redundancy: 1.21
Multiply observed: 20.67%
The resulting completeness is slightly higher than in the SortHKL case, but for actual statistics it might be better to remove the zero intensity peaks from the workspace prior to running the algorithm.
Categories: AlgorithmIndex | Crystal\Peaks
C++ source: CountReflections.cpp (last modified: 2019-07-17)
C++ header: CountReflections.h (last modified: 2018-10-05)