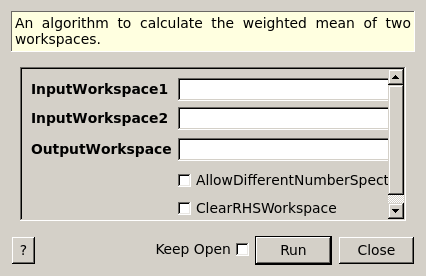
WeightedMean dialog.
Table of Contents
| Name | Direction | Type | Default | Description |
|---|---|---|---|---|
| InputWorkspace1 | Input | MatrixWorkspace | Mandatory | The name of the input workspace on the left hand side of the operation |
| InputWorkspace2 | Input | MatrixWorkspace | Mandatory | The name of the input workspace on the right hand side of the operation |
| OutputWorkspace | Output | MatrixWorkspace | Mandatory | The name to call the output workspace |
| AllowDifferentNumberSpectra | Input | boolean | False | Are workspaces with different number of spectra allowed? For example, the LHSWorkspace might have one spectrum per detector, but the RHSWorkspace could have its spectra averaged per bank. If true, then matching between the LHS and RHS spectra is performed (all detectors in a LHS spectrum have to be in the corresponding RHS) in order to apply the RHS spectrum to the LHS. |
| ClearRHSWorkspace | Input | boolean | False | For EventWorkspaces only. This will clear out event lists from the RHS workspace as the binary operation is applied. This can prevent excessive memory use, e.g. when subtracting an EventWorkspace from another: memory use will be approximately constant instead of increasing by 50%. At completion, the RHS workspace will be empty. |
The algorithm calculates the weighted mean of two workspaces. This is useful when working with distributions rather than histograms, particularly when counting statistics are poor and it is possible that the value of one data set is statistically insignificant but differs greatly from the other. In such a case simply calculating the average of the two data sets would produce a spurious result.
If each input workspace and the standard deviation are labelled 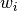 and
and 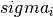 , respectively, and there
are N workspaces then the weighted mean is computed as:
, respectively, and there
are N workspaces then the weighted mean is computed as:
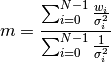
where m is the output workspace. The x values are copied from the first input workspace.
The input workspaces must be compatible with respect to size, units, and whether they are distributions or not.
Example - Perform a simple weighted mean
# create histogram workspaces
dataX1 = [0,1,2,3,4,5,6,7,8,9] # or use dataX1=range(0,10)
dataY1 = [0,1,2,3,4,5,6,7,8] # or use dataY1=range(0,9)
dataE1 = [1,1,1,1,1,1,1,1,1] # or use dataE1=[1]*9
dataX2 = [1,1,1,1,1,1,1,1,1,1]
dataY2 = [2,2,2,2,2,2,2,2,2]
dataE2 = [3,3,3,3,3,3,3,3,3]
ws1 = CreateWorkspace(dataX1, dataY1, dataE1)
ws2 = CreateWorkspace(dataX2, dataY2, dataE2)
# perform the algorithm
ws = WeightedMean(ws1, ws2)
print("The X values are: " + str(ws.readX(0)))
print("The Y values are: " + str(ws.readY(0)))
print("The E values are: " + str(ws.readE(0)))
Output:
The X values are: [ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9.]
The Y values are: [ 0.2 1.1 2. 2.9 3.8 4.7 5.6 6.5 7.4]
The E values are: [ 0.9486833 0.9486833 0.9486833 0.9486833 0.9486833 0.9486833
0.9486833 0.9486833 0.9486833]
Categories: AlgorithmIndex | Arithmetic
C++ source: WeightedMean.cpp (last modified: 2019-01-07)
C++ header: WeightedMean.h (last modified: 2019-01-07)