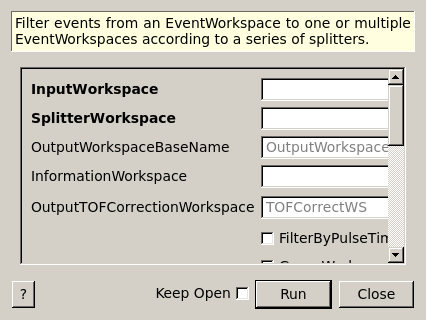
FilterEvents dialog.
Table of Contents
Filter events from an EventWorkspace to one or multiple EventWorkspaces according to a series of splitters.
| Name | Direction | Type | Default | Description |
|---|---|---|---|---|
| InputWorkspace | Input | EventWorkspace | Mandatory | An input event workspace |
| SplitterWorkspace | Input | Workspace | Mandatory | An input SpilltersWorskpace for filtering |
| OutputWorkspaceBaseName | Input | string | OutputWorkspace | The base name to use for the output workspace. The output workspace names are a combination of this and the index in splitter. |
| InformationWorkspace | Input | TableWorkspace | Optional output for the information of each splitter workspace index. | |
| OutputTOFCorrectionWorkspace | Output | MatrixWorkspace | TOFCorrectWS | Name of output workspace for TOF correction factor. |
| FilterByPulseTime | Input | boolean | False | Filter the event by its pulse time only for slow sample environment log. This option can make execution of algorithm faster. But it lowers precision. |
| GroupWorkspaces | Input | boolean | False | Option to group all the output workspaces. Group name will be OutputWorkspaceBaseName. |
| OutputWorkspaceIndexedFrom1 | Input | boolean | False | If selected, the minimum output workspace is indexed from 1 and continuous. |
| CorrectionToSample | Input | string | None | Type of correction on neutron events to sample time from detector time. Allowed values: [‘None’, ‘Customized’, ‘Direct’, ‘Elastic’, ‘Indirect’] |
| DetectorTOFCorrectionWorkspace | Input | TableWorkspace | Name of table workspace containing the log time correction factor for each detector. | |
| IncidentEnergy | Input | number | Optional | Value of incident energy (Ei) in meV in direct mode. |
| SpectrumWithoutDetector | Input | string | Skip | Approach to deal with spectrum without detectors. Allowed values: [‘Skip’, ‘Skip only if TOF correction’] |
| SplitSampleLogs | Input | boolean | True | If selected, all sample logs will be splitted by the event splitters. It is not recommended for fast event log splitters. |
| NumberOutputWS | Output | number | Number of output output workspace splitted. | |
| DBSpectrum | Input | number | Optional | Spectrum (workspace index) for debug purpose. |
| OutputWorkspaceNames | Output | str list | List of output workspaces names | |
| RelativeTime | Input | boolean | False | Flag to indicate that in the input Matrix splitting workspace,the time indicated by X-vector is relative to either run start time or some indicted time. |
| FilterStartTime | Input | string | Start time for splitters that can be parsed to DateAndTime. | |
| TimeSeriesPropertyLogs | Input | str list | List of name of sample logs of TimeSeriesProperty format. They will be either excluded from splitting if ExcludedSpecifiedLogs is specified as True. Or They will be the only TimeSeriesProperty sample logs that will be split to child workspaces. | |
| ExcludeSpecifiedLogs | Input | boolean | True | If true, all the TimeSeriesProperty logs listed will be excluded from duplicating. Otherwise, only those specified logs will be split. |
| DescriptiveOutputNames | Input | boolean | False | If selected, the names of the output workspaces will include information about each slice. |
This algorithm filters events from a single Event Workspace to one or multiple EventWorkspaces according to the SplittersWorkspace property. The Event Filtering concept page has a detailed introduction to event filtering.
The SplittersWorkspace describes much of the information for splitting the InputWorkspace into the various output workspaces. It can have one of three types
| workspace class | units | rel/abs |
|---|---|---|
| MatrixWorkspace | seconds | either |
| SplittersWorkspace | nanoseconds | absolute |
| TableWorkspace | seconds | either |
Whether the values in MatrixWorkspace and TableWorkspace is treated as relative or absolute time is dependent on the value of RelativeTime. In the case of RelativeTime=True, the time is relative to the start of the run (in the ws.run()['run_start']) or, if specified, the FilterStartTime. In the case of RelativeTime=False, the times are relative to the GPS epoch.
Both TableWorkspace and SplittersWorkspace have 3 columns, start, stop, and target which should be a float, float, and string. The event filtering concept page has details on creating the TableWorkspace by hand.
If the SplittersWorkspace is a MatrixWorkspace, it must have a single spectrum with the x-value is the time boundaries and the y-value is the workspace group index.
The optional InformationWorkspace is a TableWorkspace for information of splitters.
Some events are not inside any splitters. They are put to a workspace name ended with _unfiltered. If OutputWorkspaceIndexedFrom1=True, then this workspace will not be created.
There are a few parameters to consider when the log filtering is expected to produce a large splitter table. An example of such a case would be a data file for which the events need to be split according to a log with two or more states changing in the kHz range. To reduce the filtering time, one may do the following:
When filtering fast logs, the time to filter by is the time that the neutron was at the sample. This can be specified using the CorrectionToSample parameter. Either the user specifies the correction parameter for every pixel, or one is calculated. The correction parameters are applied as
![TOF_{sample} = TOF_{detector} * scale[detectorID] + shift[detectorID]](../_images/math/3e264675125db3f1c8d2e294463f6c0fc3a5c546.png)
and stored in the OutputTOFCorrectionWorkspace.
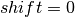 with
with
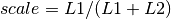 for detectors and
for detectors and 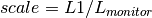 for monitors
for monitors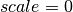 and
and
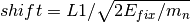 . The value supplied in
IncidentEnergy will override the value found in the workspace’s
value of Ei.
. The value supplied in
IncidentEnergy will override the value found in the workspace’s
value of Ei.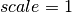 and
and
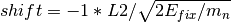 for detectors. For
monitors, uses the same corrections as Elastic.
for detectors. For
monitors, uses the same corrections as Elastic.In FilterByLogValue, EventList.splitByTime() is used. In FilterEvents, it only uses this when FilterByPulse=True. Otherwise, EventList.splitByFullTime() is used. The difference between splitByTime and splitByFullTime is that splitByTime filters events by pulse time, and splitByFullTime considers both pulse time and TOF.
Example - Filtering event without correction on TOF
ws = Load(Filename='CNCS_7860_event.nxs')
splitws, infows = GenerateEventsFilter(InputWorkspace=ws, UnitOfTime='Nanoseconds', LogName='SampleTemp',
MinimumLogValue=279.9, MaximumLogValue=279.98, LogValueInterval=0.01)
FilterEvents(InputWorkspace=ws, SplitterWorkspace=splitws, InformationWorkspace=infows,
OutputWorkspaceBaseName='tempsplitws', GroupWorkspaces=True,
FilterByPulseTime = False, OutputWorkspaceIndexedFrom1 = False,
CorrectionToSample = "None", SpectrumWithoutDetector = "Skip", SplitSampleLogs = False,
OutputTOFCorrectionWorkspace='mock')
# Print result
wsgroup = mtd["tempsplitws"]
wsnames = wsgroup.getNames()
for name in sorted(wsnames):
tmpws = mtd[name]
print("workspace %s has %d events" % (name, tmpws.getNumberEvents()))
Output:
workspace tempsplitws_0 has 124 events
workspace tempsplitws_1 has 16915 events
workspace tempsplitws_2 has 10009 events
workspace tempsplitws_3 has 6962 events
workspace tempsplitws_4 has 22520 events
workspace tempsplitws_5 has 5133 events
workspace tempsplitws_unfiltered has 50603 events
Example - Filtering event by a user-generated TableWorkspace
import numpy as np
ws = Load(Filename='CNCS_7860_event.nxs')
# create TableWorkspace
split_table_ws = CreateEmptyTableWorkspace()
split_table_ws.addColumn('float', 'start')
split_table_ws.addColumn('float', 'stop')
split_table_ws.addColumn('str', 'target')
split_table_ws.addRow([0., 100., 'a'])
split_table_ws.addRow([200., 300., 'b'])
split_table_ws.addRow([400., 600., 'c'])
split_table_ws.addRow([600., 650., 'b'])
# filter events
FilterEvents(InputWorkspace=ws, SplitterWorkspace=split_table_ws,
OutputWorkspaceBaseName='tempsplitws3', GroupWorkspaces=True,
FilterByPulseTime = False, OutputWorkspaceIndexedFrom1 = False,
CorrectionToSample = "None", SpectrumWithoutDetector = "Skip", SplitSampleLogs = False,
OutputTOFCorrectionWorkspace='mock',
RelativeTime=True)
# Print result
wsgroup = mtd["tempsplitws3"]
wsnames = wsgroup.getNames()
for name in sorted(wsnames):
tmpws = mtd[name]
print("workspace %s has %d events" % (name, tmpws.getNumberEvents()))
split_log = tmpws.run().getProperty('splitter')
entry_0 = np.datetime_as_string(split_log.times[0].astype(np.dtype('M8[s]')), timezone='UTC')
entry_1 = np.datetime_as_string(split_log.times[1].astype(np.dtype('M8[s]')), timezone='UTC')
print('event splitter log: entry 0 and entry 1 are {0} and {1}.'.format(entry_0, entry_1))
Output:
workspace tempsplitws3_a has 77580 events
event splitter log: entry 0 and entry 1 are 2010-03-25T16:08:37Z and 2010-03-25T16:10:17Z.
workspace tempsplitws3_b has 0 events
event splitter log: entry 0 and entry 1 are 2010-03-25T16:08:37Z and 2010-03-25T16:11:57Z.
workspace tempsplitws3_c has 0 events
event splitter log: entry 0 and entry 1 are 2010-03-25T16:08:37Z and 2010-03-25T16:15:17Z.
workspace tempsplitws3_unfiltered has 34686 events
event splitter log: entry 0 and entry 1 are 2010-03-25T16:08:37Z and 2010-03-25T16:10:17Z.
Example - Filtering event by pulse time
ws = Load(Filename='CNCS_7860_event.nxs')
splitws, infows = GenerateEventsFilter(InputWorkspace=ws, UnitOfTime='Nanoseconds', LogName='SampleTemp',
MinimumLogValue=279.9, MaximumLogValue=279.98, LogValueInterval=0.01)
FilterEvents(InputWorkspace=ws,
SplitterWorkspace=splitws,
InformationWorkspace=infows,
OutputWorkspaceBaseName='tempsplitws',
GroupWorkspaces=True,
FilterByPulseTime = True,
OutputWorkspaceIndexedFrom1 = True,
CorrectionToSample = "None",
SpectrumWithoutDetector = "Skip",
SplitSampleLogs = False,
OutputTOFCorrectionWorkspace='mock')
# Print result
wsgroup = mtd["tempsplitws"]
wsnames = wsgroup.getNames()
for name in sorted(wsnames):
tmpws = mtd[name]
print("workspace %s has %d events" % (name, tmpws.getNumberEvents()))
Output:
workspace tempsplitws_1 has 123 events
workspace tempsplitws_2 has 16951 events
workspace tempsplitws_3 has 9972 events
workspace tempsplitws_4 has 7019 events
workspace tempsplitws_5 has 22529 events
workspace tempsplitws_6 has 5067 events
Example - Filtering event with correction on TOF
ws = Load(Filename='CNCS_7860_event.nxs')
splitws, infows = GenerateEventsFilter(InputWorkspace=ws, UnitOfTime='Nanoseconds', LogName='SampleTemp',
MinimumLogValue=279.9, MaximumLogValue=279.98, LogValueInterval=0.01)
FilterEvents(InputWorkspace=ws, SplitterWorkspace=splitws, InformationWorkspace=infows,
OutputWorkspaceBaseName='tempsplitws',
GroupWorkspaces=True,
FilterByPulseTime = False,
OutputWorkspaceIndexedFrom1 = False,
CorrectionToSample = "Direct",
IncidentEnergy=3,
SpectrumWithoutDetector = "Skip",
SplitSampleLogs = False,
OutputTOFCorrectionWorkspace='mock')
# Print result
wsgroup = mtd["tempsplitws"]
wsnames = wsgroup.getNames()
for name in sorted(wsnames):
tmpws = mtd[name]
print("workspace %s has %d events" % (name, tmpws.getNumberEvents()))
Output:
workspace tempsplitws_0 has 123 events
workspace tempsplitws_1 has 16951 events
workspace tempsplitws_2 has 9972 events
workspace tempsplitws_3 has 7019 events
workspace tempsplitws_4 has 22514 events
workspace tempsplitws_5 has 5082 events
workspace tempsplitws_unfiltered has 50605 events
Categories: AlgorithmIndex | Events\EventFiltering
C++ source: FilterEvents.cpp (last modified: 2019-07-17)
C++ header: FilterEvents.h (last modified: 2019-06-03)
Python: FilterEvents.py (last modified: 2019-04-30)